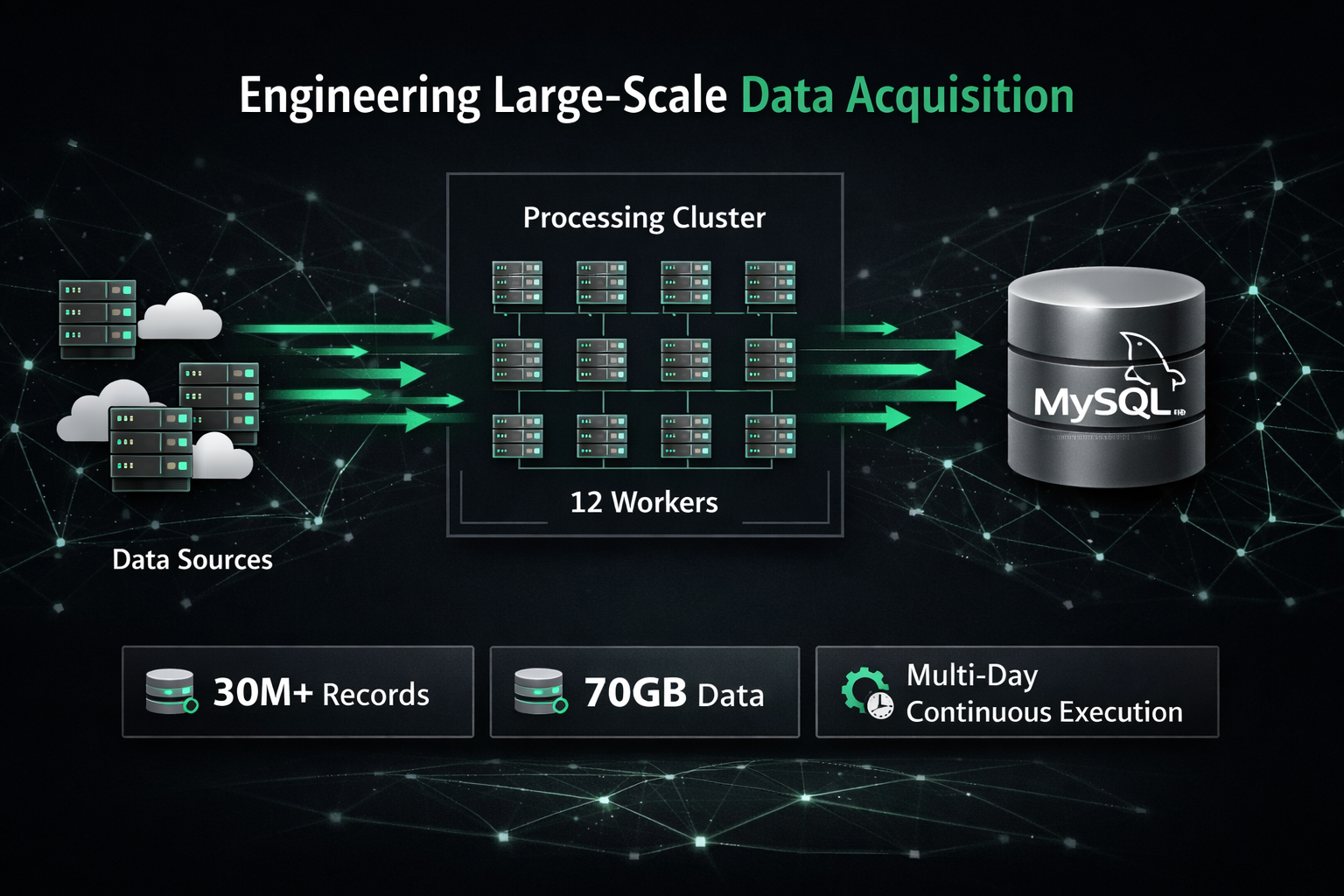
Large-scale data acquisition is not about writing a scraper. It is about engineering a system that survives scale, concurrency, failures, and time.
This article documents the architecture and execution of a production-grade data acquisition and ingestion system that processed:
- 30M+ menu records
- 352K business listings
- 2.4M menu item categories
- ~70GB of structured data
- Multi-day continuous execution
- Less than 2% initial failure rate, resolved via retry pipelines
The system was intentionally engineered for control, observability, and reliability, not shortcuts.
Design Philosophy
From day one, the system was designed around three principles:
- Predictable behavior beats raw speed
- Every failure must be recoverable
- Data correctness matters more than volume
At this scale, any weak assumption eventually breaks.
High-Level Architecture
The system consisted of four tightly coordinated layers:
- Frontend execution layer (JavaScript)
- Request/session & networking layer
- Processing & normalization layer
- Persistence & indexing layer (MySQL)
Each layer was isolated to prevent cascading failure while remaining fully observable.
Frontend Execution Layer (Raw JavaScript)
One of the most critical components was the frontend execution logic.
Instead of browser automation frameworks, I used raw JavaScript execution, injected and executed via controlled code snippets.
Execution characteristics:
- Pure JavaScript (no frameworks)
- Batch-based execution
- Recursive resolution until completion
- Explicit state tracking
- Zero reliance on UI rendering
Why this mattered:
- Minimal overhead
- Fine-grained control over execution
- Faster iteration
- Easier recovery on partial failures
Each batch processed a known subset of tasks and recursively continued until all targets were resolved.
This ensured:
- No orphaned tasks
- Deterministic progress
- Safe restarts at any point in the pipeline
Distributed Network & Proxy Layer
Network reliability was handled through a distributed proxy architecture.
Infrastructure setup:
- 20+ lightweight VPS instances (DigitalOcean)
- Each VPS acted as a controlled outbound proxy
- Health checks disabled unstable nodes
- Traffic distribution balanced across workers
This architecture provided:
- Predictable network behavior
- Isolation of network failures
- Stable long-running execution
- Easy replacement of unhealthy nodes
The system favored many small, disposable nodes over complex centralized infrastructure.
Concurrency Model & Thread Coordination
The core execution ran with:
- 12 concurrent worker threads
- Shared task queues
- Centralized state tracking
- Coordinated lifecycle management
The real challenge:
Every worker thread was:
- Actively reading tasks
- Processing complex relational data
- Writing to the same MySQL database
This required:
- Strict transaction boundaries
- Idempotent writes
- Collision-safe schema design
- Careful index strategy
Concurrency was tuned to avoid:
- Write contention
- Lock escalation
- Memory exhaustion
- Deadlocks
Native Session Handling
Native session management proved to be a major performance multiplier.
Session strategy:
- Sessions persisted per worker lifecycle
- Automatic invalidation on error signals
- Controlled recreation logic
- Scoped reuse across deep navigation paths
Benefits:
- Reduced repeated negotiation overhead
- Improved request consistency
- Lower failure rates
- Faster overall throughput
Stateless execution was deliberately avoided where it harmed efficiency.
Data Modeling & Schema Normalization
The dataset was deeply relational and required strict normalization.
Core entities:
- Business listings
- Menus
- Menu categories
- Menu items
- Add-ons
- Variants
- Pricing rules
- Metadata
- Geospatial attributes
Each entity was:
- Modeled independently
- Assigned stable identifiers
- Linked via foreign keys
- Designed for incremental processing
This enabled:
- Deduplication
- Partial reprocessing
- Safe retries
- Long-term maintainability
Geolocation & Spatial Indexing
Location accuracy was a first-class requirement.
Geospatial handling:
- Latitude & longitude normalized per listing
- Precision validation during ingestion
- Spatial indexes applied at the database level
- Optimized queries for radius-based search
This allowed:
- Accurate geographic filtering
- Fast proximity queries
- Scalable location-based operations
Geolocation was engineered as infrastructure, not metadata.
High-Throughput Persistence Layer (MySQL + Raw PHP)
At this scale, the write path determines success or failure.
Persistence strategy:
- Raw PHP write layer
- No heavy ORM abstractions
- Batch inserts where possible
- Deferred index creation
- Controlled transaction scopes
- Streaming data writes to limit memory usage
Why raw PHP:
- Predictable performance
- Minimal overhead
- Full control over execution
- Better handling of massive write volumes
This layer handled millions of writes reliably, where abstraction-heavy approaches would have collapsed.
Failure Detection, Retry & Recovery
Failures were treated as normal operating conditions.
Recovery strategy:
- Every request outcome logged
- Failed tasks persisted separately
- Independent retry pipelines
- Multiple retry passes supported
- Idempotent writes ensured safe reprocessing
Results:
- Initial failure rate: ~2%
- Post-retry unresolved failures: near zero
The system could be:
- Stopped
- Restarted
- Partially rerun without data corruption or duplication.
Observability & Control
Visibility was essential for multi-day execution.
Observability features:
- Structured logging
- Per-thread metrics
- Progress checkpoints
- Failure categorization
- Throughput monitoring
This allowed proactive intervention before issues escalated.
Why This Architecture Worked
This system succeeded because it prioritized:
- Engineering discipline
- Controlled complexity
- Explicit state management
- Reliable persistence
- Recovery-first thinking
No single component was extraordinary — the composition was.
Final Results
- 70GB+ of structured data
- Millions of normalized records
- Accurate geospatial indexing
- Multi-day uninterrupted execution
- Recoverable, restart-safe pipeline
This was not about scraping faster. It was about building systems that don't break when they matter most.
Why This Matters for Real Businesses
Businesses face similar challenges when:
- Aggregating external data
- Processing large datasets
- Running long batch jobs
- Scaling ingestion pipelines
- Maintaining data integrity under load
This project demonstrates how engineering-first thinking enables scale — without unnecessary infrastructure or fragile shortcuts.
Want to Build Systems Like This?
If you're dealing with:
- Large-scale data acquisition
- Distributed execution
- High-concurrency write workloads
- Geospatial data
- Long-running batch pipelines
I help design systems that stay reliable under pressure.
👉 Reach out for a technical discussion.